2019.3.3高中部集训
知识清单
- 字典树
- 自动机
- 哈希
笔记
一、KMP
引入:众所周知,普通的字符串匹配非常慢(其实不慢,期望复杂度,但是非常容易卡成。所以就发明了,用3个作者的名字命名。
算法:我太懒了,不想写出的模拟过程。的精髓是:能在失配时直接跳到可能匹配的地方。
要把失配数组建立在匹配串意义下,而不是文本串。因为匹配串更加灵活。
生成失配数组:匹配值是指前缀和后缀的最长共有元素长度(前缀指除了最后一个字符以外的全部头部组合,后缀指除了第一个字符以外的全部尾部组合)
匹配串为“ABCDABD”
1、“A":
匹配值:0
前缀:NULL
后缀:NULL
2、“AB”:
匹配值:0
前缀:A
后缀:B
3、“ABC”:
匹配值:0
前缀:A、AB
后缀:BC、C
4、“ABCD”:
匹配值:0
前缀:A、AB、ABC
后缀:BCD、CD、D
5、“ABCDA”:
匹配值:1
前缀:[A]、AB、ABC、ABCD
后缀:BCDA、CDA、DA、[A]
6、“ABCDAB”:
匹配值:2
前缀:A、[AB]、ABC、ABCD、ABCDA
后缀:BCDAB、CDAB、DAB、[AB]、B
7、“ABCDABD”:
匹配值:0
前缀:A、AB、ABC、ABCD、ABCDA、ABCDAB
后缀:BCDABD、CDABD、DABD、ABD、BD、D
- 实现生成数组:
int k=0; for(int i=1;i<len2;i++){ while(k && s2[i]!=s2[k]) k=kmp[k]; if(s2[i]==s2[k]) kmp[i+1]=++k; }- 最后的字符串匹配:
for(int i=0; i<len1; i++){ while(k && s1[i]!=s2[k]) k=kmp[k]; if(s1[i]==s2[k]) k++; if(k==len2) printf("%d\n",i-len2+2); }
- 标程:
#include<cstdio> #include<algorithm> #include<cstring> using namespace std; const int maxn=1000010; char s1[maxn],s2[maxn]; int kmp[maxn]; int main() { scanf("%s",s1); scanf("%s",s2); int len1=strlen(s1); int len2=strlen(s2); int k=0; for(int i=1;i<len2;i++) { while(k && s2[i]!=s2[k]) k=kmp[k]; if(s2[i]==s2[k]) kmp[i+1]=++k; } k=0; for(int i=0; i<len1; i++){ while(k && s1[i]!=s2[k]) k=kmp[k]; if(s1[i]==s2[k]) k++; if(k==len2) printf("%d\n",i-len2+2); } for(int i=1; i<=len2; i++)printf("%d ",kmp[i]); return 0; }
二、字典树
引入:因为所有的树形结构都有一个基本特点:元素与元素之间的关系为继承的一对多的关系。所以字典树可以很方便的储存和查找字符串。下面就是个字典树
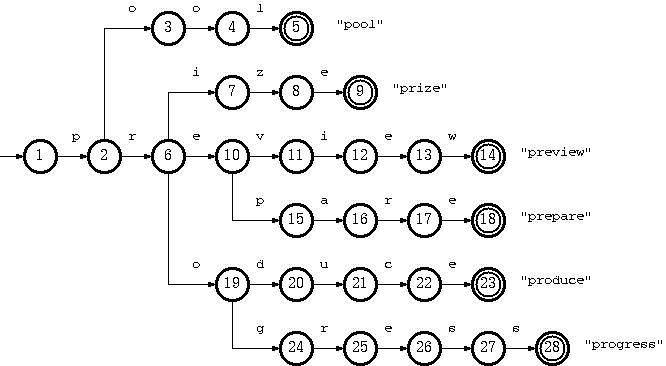
字典树算法:我太懒了,直接贴注释
- 初始化:
struct node{ int son[MAXS];//子节点的分支个数 int size,end;//所在的字符串个数,是字符串末尾的个数 }Trie[MAXN];- 插入:
void insert(int t[],int l){//插入数组t[],插入个数l int o=root;//当前结点,初始化为root根节点 for (int i=1;i<=l;i++){ Trie[o].size++; if (!Trie[o].son[t[i]])//需要的子节点没有就添加子节点 Trie[o].son[t[i]]=++tot; o=Trie[o].son[t[i]];//更新当前节点 } Trie[o].size++;//表面的意思 Trie[o].end++;//表面的意思 return; }- 查询:一个字符串是否是给定字符串集合中某个前缀
bool query(int t[],int l){ int o=root; for (int i=1;i<=l;i++){ if (!Trie[o].son[t[i]]) return false; o=Trie[o].son[t[i]]; } return true; }例题:[【洛谷】 []秘密消息 ](https://www.luogu.org/problemnew/show/P2922)
- 分析:普通的字符串储存和前缀匹配,直接使用字典树来做。
- 标程:
#include <iostream> #include <cstdio> using namespace std; struct node{ int son[2]; int size,end; }Trie[500005];//题目中的数据范围好像标错了QAQ int tot,root; int m,n; void insert(int t[],int l){ int o=root; for (int i=1;i<=l;i++){ Trie[o].size++; if (!Trie[o].son[t[i]]) Trie[o].son[t[i]]=++tot; o=Trie[o].son[t[i]]; } Trie[o].size++; Trie[o].end++;//不能直接=1,储存的是在这个字符结束的字符串个数 return; } int query(int t[],int l){ int o=root,ans=0; for (int i=1;i<=l;i++){ ans+=Trie[o].end; if (!Trie[o].son[t[i]]) return ans; o=Trie[o].son[t[i]]; } return ans+Trie[o].size;//记得最后结点所在的字符串格式也要加上! } int main(){ int len,t[10005]={}; scanf("%d%d",&m,&n); for (int i=1;i<=m;i++){ scanf("%d",&len); for (int j=1;j<=len;j++) scanf("%d",&t[j]); insert(t,len); } for (int i=1;i<=n;i++){ scanf("%d",&len); for (int j=1;j<=len;j++){ scanf ("%d",&t[j]); } printf("%d\n",query(t,len)); } return 0; }